
Chinese labs drop some incredible models
Week 45 of Coding with Intelligence

📰 News
OpenCoder 8B: The Open Cookbook for Top-Tier Code Large Language Models
Reproducible LLMs from a Chinese lab, very awesome contribution and actually impressive performance, outperforming the very strong Qwen 2.5 Coder 7B.
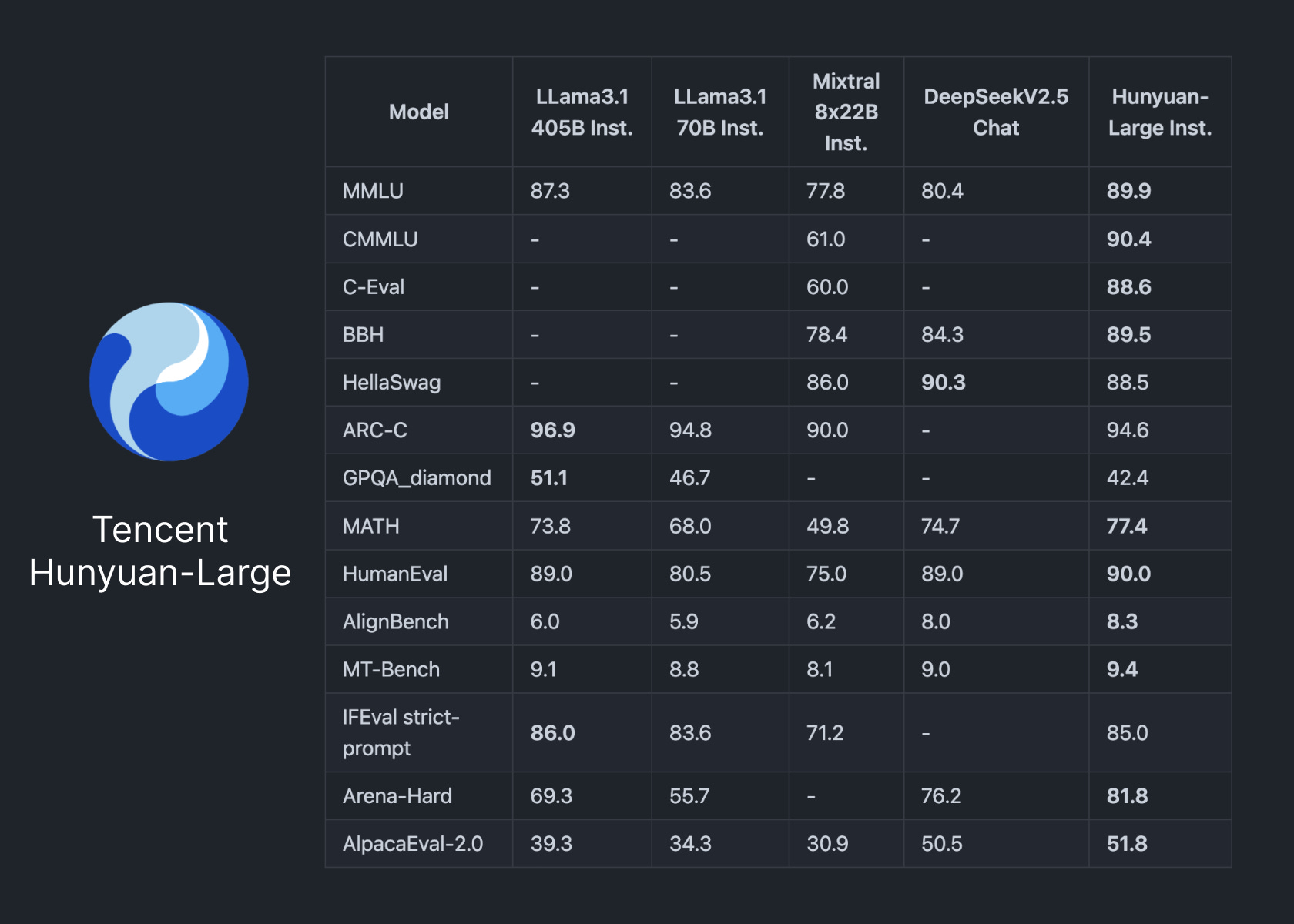
Hunyuan-Large: A52B MoE by Tencent
This supposedly beats Llama 3.1 405B on a number of benchmarks, very impressive. License is non EU and sub 100M users.
Hunyuan3D-1 an open source Text-to-3D and Image-to-3D model by Tencent
Impressive object generation! Game devs/AR/VR enthusiasts will love this. Homepage https://3d.hunyuan.tencent.com/
Mistral launches Moderation API
Fairly high accuracy across all categories. $0.1 per 1M input tokens.
FrontierMath: A math benchmark testing the limits of AI
Hard evals that LLMs can't crack have a tendency to accelerate the field. This new math eval by Epoch AI is a banger release that puzzles even o1-preview, Claude 3.5 Sonnet (10-22), and Gemini 1.5 Pro (002) all scoring 1-2%.
FLUX1.1 [pro] Ultra and Raw Modes
4MP in sub 10 seconds is very impressive of an image model with this level of quality. Go team Black Forest Labs! Raw Mode is a nice alternative to the Midjourney-vibe we've been getting from most text-to-image models.
OpenAI launches predicted outputs feature
"Predicted Outputs enable you to speed up API responses from Chat Completions when many of the output tokens are known ahead of time. This is most common when you are regenerating a text or code file with minor modifications." Edit style prompts can be 2x faster, as a rule of thumb.
It costs about a third of 3.5 Sonnet but is meaningfully worse. It's a bit faster than 3.5 Sonnet but only by about 16%. I don't think this is Anthropic's best launch.
Google's security effort under Project Zero has successfully used LLMs to find code vulnerabilities. Awesome and highly technical writeup.
hertz-dev: open-source base model for conversational audio generation
Permissively licensed, impressive samples, great write-up.
📦 Repos
AllenAI's OLMo's models training code ported to AMD stack. Neat contribution to accelerate AMD <> NVIDIA race.
Tess-R1 Limerick (Llama-3.1-70B)
Another test-time-compute built-in finetune of Llama 3.1 70B that claims improved benchmark performance. Explore and leave in the comments how well you think it does. Here's a HF Space https://huggingface.co/spaces/poscye/chat-with-tess
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Interesting agent stack by Microsoft - equipping LLMs with browsing, terminal, filesystem capabilities for open ended goal accomplishment.
RaVL: Discovering and Mitigating Spurious Correlations in Fine-Tuned Vision-Language Models
This work from a team at Stanford finds a way to identify and mitigate spurious correlation in Vision Language Models.
📄 Papers
B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable
Must read if you're interested in interpretability work for deep neural networks. This paper focuses on the image domain mainly. By folks from Max Planck, Kyutai & more.
Cosmos Tokenizer: A suite of image and video neural tokenizers
Important work in tokenization of multimodal content, tokenizers can form a glass ceiling for performance because of information lost in the process of tokenizing content. Amazing work by NVIDIA and published with a very high level of detail!
A Scalable Communication Protocol for Networks of Large Language Models
This approach to allowing agents to communicate for agent-swarm like applications looks promising. If you've been put off by the verbiage usually used in "distributed agent" work then this will be a fresh, well thought out piece of research.
ADOPT: Modified Adam Can Converge with Any β2 with the Optimal Rate
Various folks on X have been touting this as being strictly better than Adam, meaning they would always get better performance from this compared to running Adam, and that would be a large feat. Better optimizers matter when efficiency gains translate into thousands, tens of thousands or even larger dollar/energy savings at large scale pre- and finetuning.
📱 Demos
Vision Language Models are In-Context Value Learners
Try the Interactive Illustration, it impressively demonstrates how complementary robotics and vision language models are. Expect acceleration of Robotics especially in control like bimanual manipulation tasks. By DeepMind, UPenn, and Stanford.
📚 Resources
Simon Willison exploring tool use feature for his `llm` CLI project
Cool GitHub issue!
Want more? Follow me on X! @ricklamers