
Claude 4, Qwen 3 & DeepSeek R1 0528: model capabilities keep increasing
Week 22 of Coding with Intelligence

Note: this newsletter edition got a bit long, open in the browser to see the full post.
📰 News
OpenAI releases cloud coding agent Codex
Confusingly named Codex, which is also the name of their open source (Apache 2.0) CLI coding agent they released just a month ago. Integration directly into ChatGPT and strong native GitHub integration bring cloud SWE agents closer to their AI-everything app ChatGPT. It is powered by codex-1 a finetune of o3 focused on SWE tasks.
ResembleAI releases strong open weight TTS model: chatterbox
Impressive quality, supports voice cloning out of the box. Their emotion exaggeration control is unique among the open models which tend to be quite bland.
Google releases Jules: a Devin/Codex background SWE agent competitor
A growing landscape of GitHub-centric background SWE agents complementing "inner dev loop" tools like Cursor and Windsurf, try & see which one you like.
Terminal-Bench: a terminal use benchmark
Does what it says on the tin, very neatly executed benchmark. It was quickly picked up by frontier labs as its performance was featured in the Anthropic Claude 4 release. Not saturated yet with SOTA models reaching ~40%. Tasks vary from building the Linux source from scratch to training ML models from terminal.
Cool & importantly open work pushing the frontier of open/small model code generation/SWE agent models. Comfortably beats GPT-4.1-mini, Claude 3.5 Haiku onSWE-Bench Verified.
Black Forest Labs strikes again: FLUX.1 Kontext
A new image generation and edit model that allows for prompting with text and image inputs while being remarkably good at reusing image inputs to point of allowing very granular edits. BFL style they have both open weight and proprietary models, preserving the highest quality models for paid consumption. They didn't release the open weight version yet, supposedly, because of safety/misuse concerns. My first impression is that it outperforms Gemini 2.0 image outputs and ChatGPT's image generation model GPT-image-1 on image editing quality.
o3 used to find CVE remote zeroday in Linux kernel
There are many memes of vibe coded software being especially vulnerable because of a lack of cyber security experience of the vibe coding authors. This o3 result shows the other side of the coin and shows that using the most powerful LLMs have the ability to scan (as always-on background processes perhaps) code to identify otherwise overlooked critical security issues in code that lives in production.
AlphaEvolve: algorithm design by combining search with strong code generation models
One cited algorithm contribution was a speedup of a kernel used in training Gemini, speeding up that particular kernel by 23%. It also found a 32% faster variant of the original FlashAttention kernel.
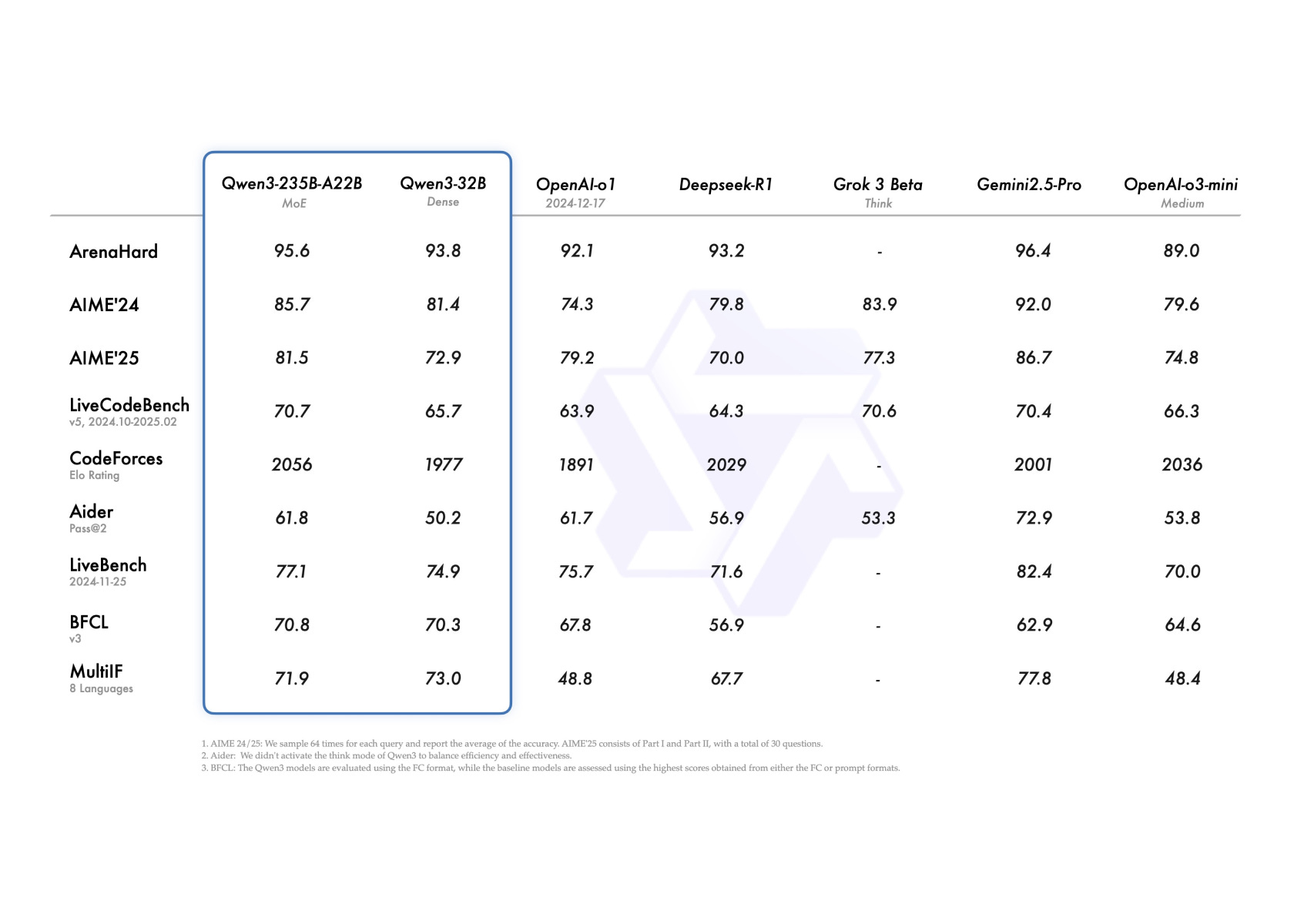
Incredible release, both dense (up to 32B) and MoE (up to 235B-A22B) models. Competitive with and sometimes outright outperforming frontier models like o1, R1, Gemini 2.5 Pro, o3-mini. System prompt based control for enabling/disabling reasoning/thinking. Broad language support, touting 119 supported languages. Increased focused on agentic use cases with strong BFCL v3 performance (useful for MCP support).
DeepSeek update R1: 0528. More reasoning tokens, higher benchmark scores
Some cherry picked benchmark deltas between R1 and R1 0528:
GPQA-Diamond (Pass@1) from 71.5 to 81.0 (o3 83.3, Gemini 2.5 Pro 0506 83.0)
LiveCodeBench (2408-2505) (Pass@1) from 63.5 to 73.3 (o3 77.3, Gemini 2.5 Pro 0506 71.8)
SWE Verified (Resolved) from 49.2 to 57.6
Tau-Bench pass@1 63.9 (Retail) (which is approximately gpt-4o-2024-11-20 level which scores 62.61, see https://hal.cs.princeton.edu/taubench_retail)Orpheus-TTS: strong open-weight TTS model
Impressive quality, repo includes finetuning scripts to tune on speaker audio you have.
📦 Repos
Anthropic open sources some of their interpretability work around circuit tracing in LLMs
Anthropic doesn't have a track record of open sourcing much of anything, so this release is a welcome one, helping others to understand LLMs more deeply. As the capability of models increases we will depend on them for more critical use cases, for which, it would be prudent to understand how LLMs arrive at one answer versus another.
uvx clai: minimalist terminal LLM chat app
Neat project by the folks behind Pydantic AI, just run `uvx clai` in the terminal with API keys set in your envs and you're set.
Bytedance releases unified Multimodal model
Text input, image input, image editing, image generation, and reasoning all in one model. Very interesting artifact to study to understand how these are brought together in a single model.
marin: open-source framework for the research and development of foundation models
Cool education focused project on all the stages involved in training foundation models. Also check out https://marin.community/
📄 Papers
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
Nice paper exploring FP4 training and demonstrating promising results against FP16 and FP8 on the NVIDIA Blackwell platform. Particularly neat that they open source the working FP4 training code.
Reasoning All The Things! This paper introduces test-time-compute for the reward model used in RL post-training itself. The idea is that with stronger reward models we can improve the signal for training LLMs with RL. The experiments in this paper show that reasoning reward models improve over non-reasoning counterparts. In addition to the research they publish the weights of the pretrained reasoning reward model (on HF).
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
Work by Meta showing how LLM judges can be improved for use in RL LLM training.
Think Only When You Need with Large Hybrid-Reasoning Models
Important topic: adaptively using test-time-compute only when the question/prompt asks for it. An exploration by Microsoft shows a feasible approach for deciding the budget adaptively.
Parallel Scaling Law for Language Models
Another scaling dimension proposed by the Qwen team: "increasing the model's parallel computation during both training and inference time". In particular, latency is reduced because of the ability to non-sequentially increase scaling reducing wall clock times.
GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents
A new SWE bench with 102 challenging optimization tasks across 10 codebases, SOTA gets 5% (Claude 4).
Hardware-Efficient Attention for Fast Decoding
"This work redesigns attention to perform more computation per byte loaded from memory to maximize hardware efficiency without trading off parallel scalability." They introduce Grouped-Tied Attention (GTA) and Grouped Latent Attention (GLA) improving over Grouped-Query Attention (GQA) and Multi-head Latent Attention (MLA) respectively.
From the same authors that brought Mamba SSM models (Tri Dao).
It will be interesting to see whether this new hardware optimized attention variant will garner much adoption.Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
Interesting finding on how RL post-training is naturally sparse and only updates 5-30% of model weights to achieve improved performance.
📚 Resources
Lilian Weng (ex-OpenAI, now Thinking Machines) on reasoning models
Nice survey blog post of the techniques and considerations involved in reasoning models. Especially the external tools during reasoning section is worth checking out.
Stanford lab explores using AI coding models to write compute kernels
>They are performing close to or in some cases even beating the standard expert-optimized production kernels shipped in PyTorch
Some numbers from the blog post:
Matmul (FP32): 101.3% performance of FP32 torch.matmul; problem size: 4096x4096 square matrices
Conv2D: 179.9% performance of FP32 torch.nn.Conv2D; problem size: (100, 3, 224, 224) input tensor, conv(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2)
Softmax: 111.8% performance of FP32 torch.softmax; problem size: (4096, 65536) input tensor
LayerNorm: 484.4% performance of FP32 torch.nn.LayerNorm; problem size: (16, 64, 256, 256) input tensor
Conv2D + ReLU + MaxPool: 290.1% performance of FP32 torch reference, 189.0% performance of FP32 torch.compile() reference; problem size: (100, 3, 224, 224) input tensor, conv(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2), maxpool(kernel_size=3, stride=2)[Video] Cursor team discusses superhuman coding model training
A conversation about RL for coding models, interesting thoughts around how to design RL rewards focused on more subjective areas like shorter code being better than longer more verbose code solutions.
[Video] Anthropic Technical Staff on Unsupervised Learning (Redpoint) pod
On how coding models are already accelerating research progress, coding performance as a signal for model quality & more.
Interesting detailed examples of undesirable model behaviors like snitching the user and self preservation. Great to see them discussed in the open, although expectedly, some worried responses across the interwebs because of these behaviors. 120 pages with lots detailed examples. An interesting result (p. 110) was that Claude 4 Opus was able to train a quadruped using RL in one of its runs (beating an expert baseline, under a constrained training budget). This shows that models are getting better at accelerating ML research itself, since neither Claude Sonnet 3.7 or Claude Sonnet 4 were able to beat the expert baseline threshold once.
Want more? Follow me on X! @ricklamers