
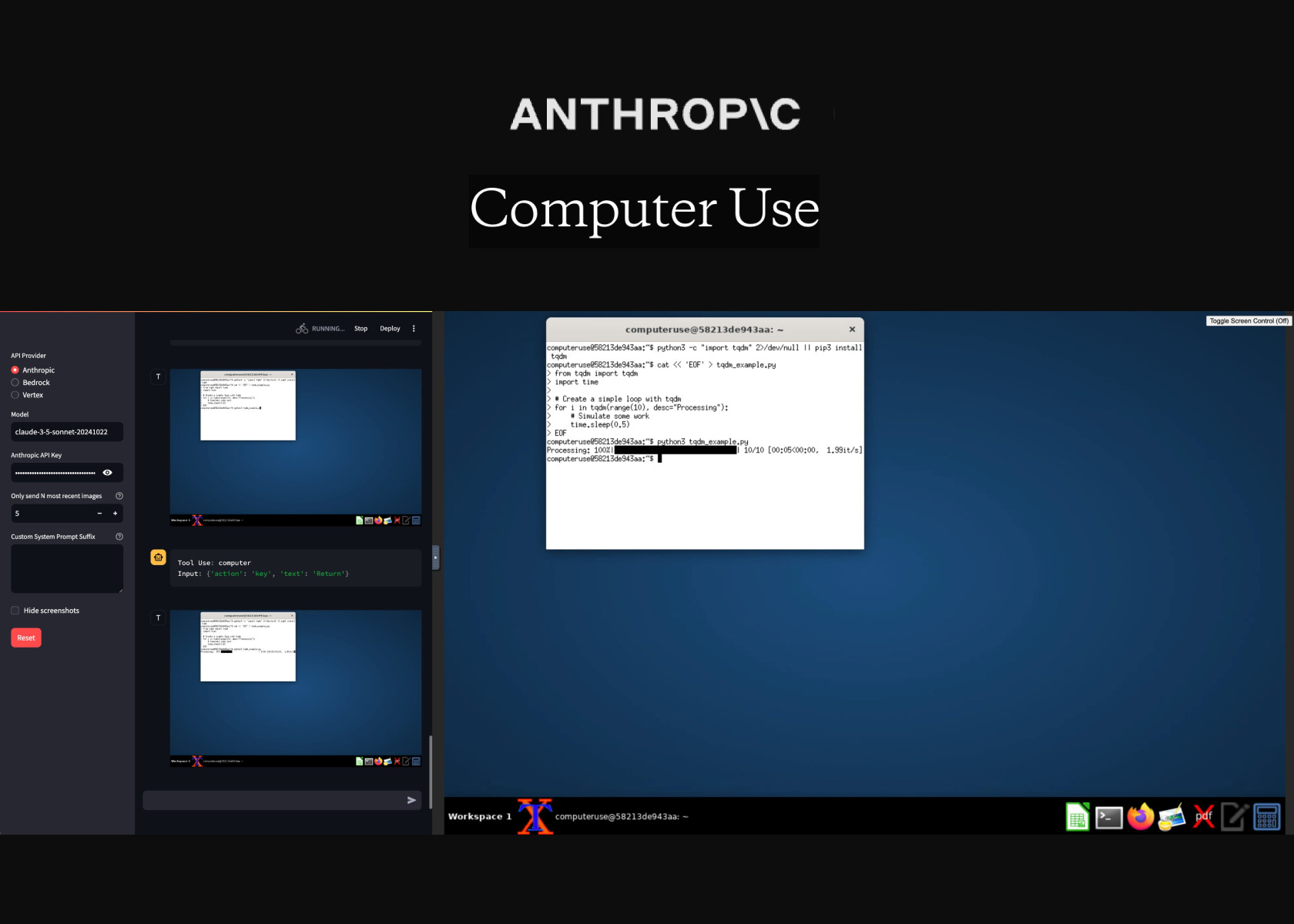
Claude Computer Use: RPA on steroids
Week 43 of Coding with Intelligence

What a BUSY week! Both for me personally (Sunday newsletter day, yay!) and in AI at large. I think everyone saw the Claude Computer Use release and tried answering the question: how ready is this? See this week’s resources for a hint of the risks currently involved and play with it on your device through Agent.exe - proceed with caution!
📰 News
Claude Sonnet 3.5 20241022 releases tops Aider leaderboard
For more about upgraded Claude 3.5 Sonnet and Claude 3.5 Haiku see Anthropic's blog post https://www.anthropic.com/news/3-5-models-and-computer-use
Mochi 1 Preview: open source text-to-video model
Samples are impressive. It's great to see a push for open source text-to-video. More people can experiment, learn about mainstream approaches to text-to-video and of course tons of cool clips to generate at compute-cost-price.
Runway releases Act-One: expressive character performance
Works by transferring character performance from a source video to a target generated character. Interestingly, still depends on convincing human performance.
Ideogram releases Dingboard like feature called "Canvas"
Companies in AI move fast and aren't afraid to ~steal~borrow good ideas from each other.
IBM introduces Granite 3.0 models
Model is close to Llama 3.1 8B at 8B size. Released under Apache 2.0.
Microsoft releases OmniParser: a UI vision extraction model
"OmniParser is a general screen parsing tool, which interprets/converts UI screenshot to structured format, to improve existing LLM based UI agent."
📦 Repos
E2B releases Desktop Sandbox feature beta
Jumping on the Claude Computer Use bandwagon. Awesome to see them move fast.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Implementation of the identically titled paper. Awesome efficiency work by the MIT HAN Lab.
Anthropic Computer Use reference implementation
A containerized Linux desktop for isolated LLM-powered computer use. Fun experiment, evals are missing. Related docs https://docs.anthropic.com/en/docs/build-with-claude/computer-use
Inf-CLIP: Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
What is very exciting about this result is that most step-change performance unlocks come from discovering computational efficiencies that allow for further scaling. Scale Is All You Need!
bitnet.cpp: the official inference framework for 1-bit LLMs
E.g., BitNet b1.58, by Microsoft. Acceleration is still suboptimal because the lack of direct hardware support.
Moonshine: new open source ASR
Licensed under MIT, claims to outperform Whisper "better than similarly-sized Whisper models from OpenAI".
Structured generation in Rust
📄 Papers
LLaVA-Video-(7B|72B) by LLaVA team
Impressive adaptation of open source for video understanding. Includes Hugging Face checkpoints, dataset and training code.
xGen-MM-Vid (BLIP-3-Video): You Only Need 32 Tokens to Represent a Video Even in VLMs
Interesting work by Salesforce on video encoding.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Interesting work to achieve higher inference performance, not clear which tasks suffer dramatically from the layer skipping described in the paper.
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World
The results point to collapse due to presence of synthetic data depends on a lack of real data, as long as it is present, synthetic data in the mix doesn't seem to result in a performance collapse.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
Addition is All You Need for Energy-efficient Language Models
Interesting ideas for making LLMs more efficient but doesn't definitively show whether performance holds up at the highest end of the performance spectrum (e.g. Llama 405B on complex reasoning).
Selective Attention Improves Transformer
Interesting idea that intuitively makes sense: not everything in the context window matters for predicting the next token. The authors present an approach to selectively applying attention to the context window.
Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
"Inspired by classical deep RL literature, we propose separating generation and learning in RLHF. This enables asynchronous generation of new samples while simultaneously training on old samples, leading to faster training and more compute-optimal scaling." and "Finally, we verify the scalability of asynchronous RLHF by training LLaMA 3.1 8B on an instruction-following task 40% faster than a synchronous run while matching final performance." awesome work in a deep cross-collaboration between Mila, Allen Institute for AI and DeepMind.
📱 Demos
Claude Computer Use on your actual computer
Needless to say, this is very risky to run. But it's pretty cool!
📚 Resources
OpenAI introduces sCM: breakthrough in image generation speeds
Hailuo SOTA Text|Image-to-Video model
Very impressive results.
o1 mechanism rumors could be useful for replication
By Philipp Schmid from Hugging Face. He draws comparison to the Stream of Search people released by Stanford researchers in April 2024.
Epoch AI shares a Machine Learning Hardware Database
AMD MI325X and GB200 unsurprisingly take the performance crown. Cool dataset!
Vectara Hallucination leaderboard
Zhipu AI GLM-4-9B-Chat is a surprising #1 scoring model
Claude ships Analysis tool to Claude web using JS sandboxing
Short exploration by Simon Willison
ZombAIs: From Prompt Injection to C2 with Claude Computer Use
Great example of Computer Use vulnerabilities. It's great Anthropic and E2B are pushing computer using LLMs forward but we need clear demonstrations of how they are vulnerable to security risks. The author of Embrace The Red does a great job. They show an E2E example of getting an agent to run malware on the target VM (still sandboxed).
Want more? Follow me on X! @ricklamers
Nice edition.
Btw do you know if anyone uses xAI?