
Full World simulation just had its ImageNet moment
Week 44 of Coding with Intelligence

I don’t believe folks are grasping the implications of this achievement yet. But the ability to simulate full world environments at increasingly higher levels of fidelity will usher in an era of robotics and real-world reasoning the consequences of which are hard to fully comprehend. Incredible work from the folks at Decart.
📰 News
OpenAI introduces SimpleQA benchmark
In an attempt to curate unsaturated benchmarks. Note, OpenAI has still done significantly more for open source than Anthropic. Something to ponder about :) OpenAI's o1-preview gets ~42% and interestingly also refuses to answer (instead of just hallucinating).
Recraft v3: most powerful (closed) image generation model
They also launch with an API. It's number one on Artificial Analysis arena leaderboard. https://artificialanalysis.ai/text-to-image/arena?tab=Leaderboard
📦 Repos
Very cool project by Michael Feil from Gradient AI.
Progress on o1 repro: MCTSr: Mathematic as a Blackbox for LLM
Early stage of a project attempting to reproduce o1, good source of raw ideas if you're working on this yourself.
SmolLM2: powerful 1.7B SLM (small language model)
Great model by Loubna Ben Allal from Hugging Face. Beats Qwen2.5-1.5B in multiple categories.
📄 Papers
MrT5: Dynamic Token Merging for Efficient Byte-level Language Models
I've been very interested in a tokenization-free approach to LLMs and this paper from Stanford nails it. Check this out if you think tokenizers are bottlenecking LLMs too!
Bayesian scaling laws for in-context learning
Interesting approach to modeling scaling laws for In-context Learning ability of LLMs.
"When applied to text-to-speech (TTS), these models (AR Transformers) tend to drop or repeat words or produce erratic output, especially for longer utterances. In this paper, we introduce enhancements aimed at AR Transformer-based encoder-decoder TTS systems that address these robustness and length generalization issues."
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
By Meta AI.
Image2Struct: Benchmarking Structure Extraction for Vision-Language Models
Useful new benchmarks for VLMs. VLMs are often used for structured extraction in practice, so this benchmarks is not very academic but well aligned with applied quality needs. By Percy Liang's group at Stanford.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
"reduces the number of video tokens while preserving visual details of long videos" neat! By folks from Meta AI, a video content powerhouse.
Anon ICLR submission: Towards Learning to Reason at Pre-Training Scale
Interesting idea! "given the first tokens from a large pre-training corpus, the model generates a CoT and receives a reward based on how well the CoT helps predict the following tokens"
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
By Google DeepMind.
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Researchers might not have tons of compute, but luckily they are smart. This paper solves the problem "When architectural modifications (e.g., channel dimensions) are introduced, the entire model typically requires retraining from scratch". This computational efficiency gain can spur faster iteration of architectural ideas, Neural-Architecture-Search let's go!
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Very strong open source non-autoregressive TTS model. Demo space on Hugging Face https://huggingface.co/spaces/amphion/maskgct
📱 Demos
OmniParser running in the browser with Transformer.js
Very impressive and useful demo showing how to run OmniParser in the browser directly. As others remarked on X, this has potential to be a core building block for browser extensions.
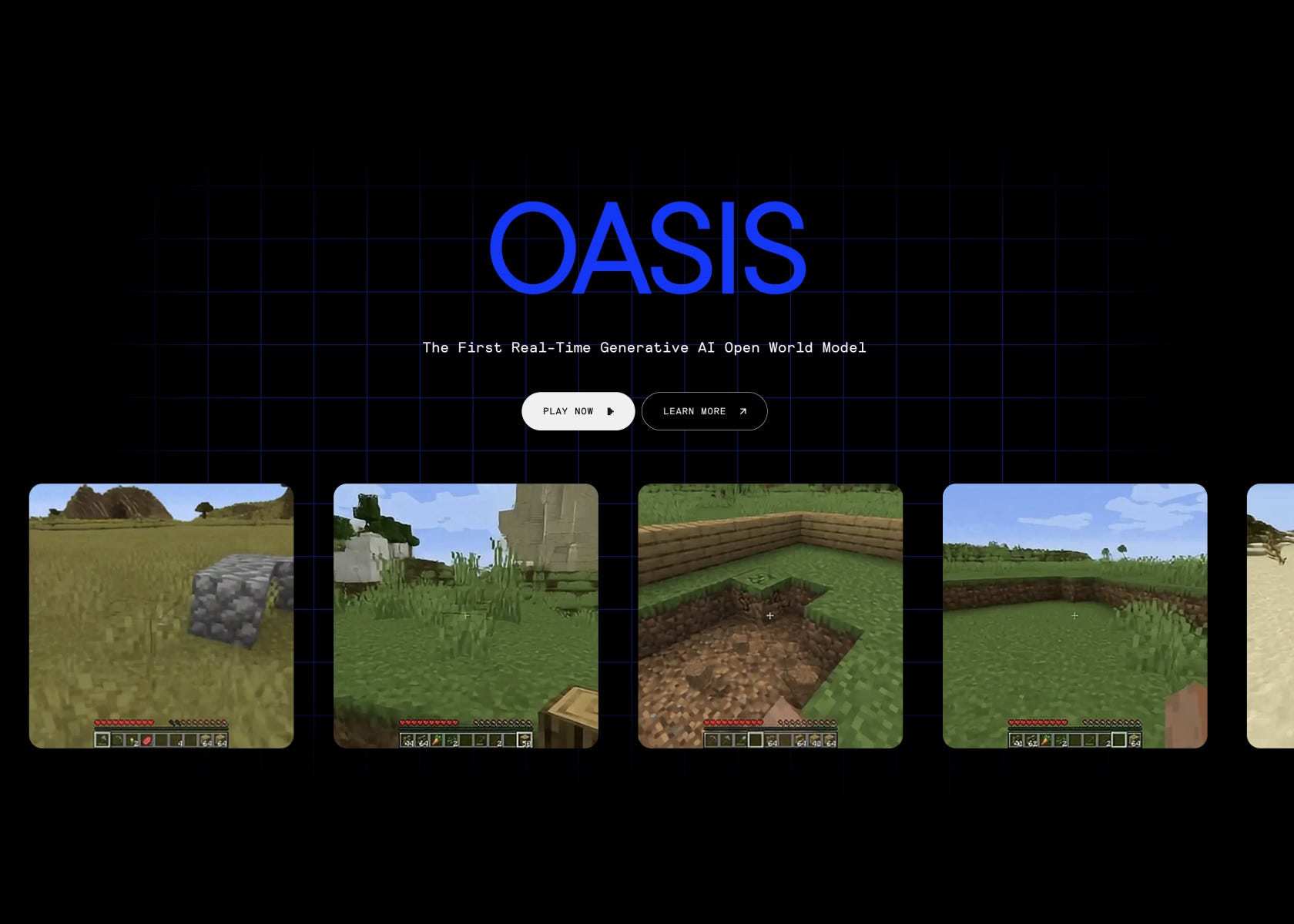
Decart launches Oasis: playable simulated Minecraft
This is a phenomenal achievement. It sets the stage for full world simulation. Remember what the first generated images/videos looked like. What makes this launch even more remarkable is that both weights and an interactive web demo with a limited queue are available. Just WOW.
AlignEval: a game/tool to help you build and optimize LLM-evaluator
Very cool project! Source is on GitHub. And this X thread
📚 Resources
It's built on top of Gemini's multimodal capabilities.
LLM as a judge for business value by Hamel Husain
You won't find better applied AI findings than this.
OpenAI Audio generation endpoint
Note this is separate from real-time audio. It allows these combinations: text in → text + audio out audio in → text + audio out audio in → text out text + audio in → text + audio out text + audio in → text out
[Video] Learning to Reason, Insights from Language Modeling
By Noah D. Goodman a researcher from Stanford.
Want more? Follow me on X! @ricklamers