
Gemini 2.0: is Google finally where everyone expected it to be?
Week 49 + 50 of Coding with Intelligence

This week covers 41 (!) updates about what’s happening in AI: spoiler - a lot. I’m sorry I had to skip y’all for a week but it just was so busy at Groq (we shipped Llama 3.3 70B + specdec version - this runs it at over 2000 tok/s on certain queries, check it out!). Enjoy this week’s update ✌️
📰 News
DeepMind releases Genie 2: a foundational world model
Similar to GameNGen by Google Research earlier and Oasis by Decart. It allows a user to provide inputs to have real-time control over a world simulation engine. It seems to suffer from similar issues of earlier attempts like persistence. "we believe Genie 2 is the path to solving a structural problem of training embodied agents safely while achieving the breadth and generality required to progress towards AGI". You can be sure that teams like the folks behind the Tesla Optimus humanoid robot are experimenting with these world simulation techniques.
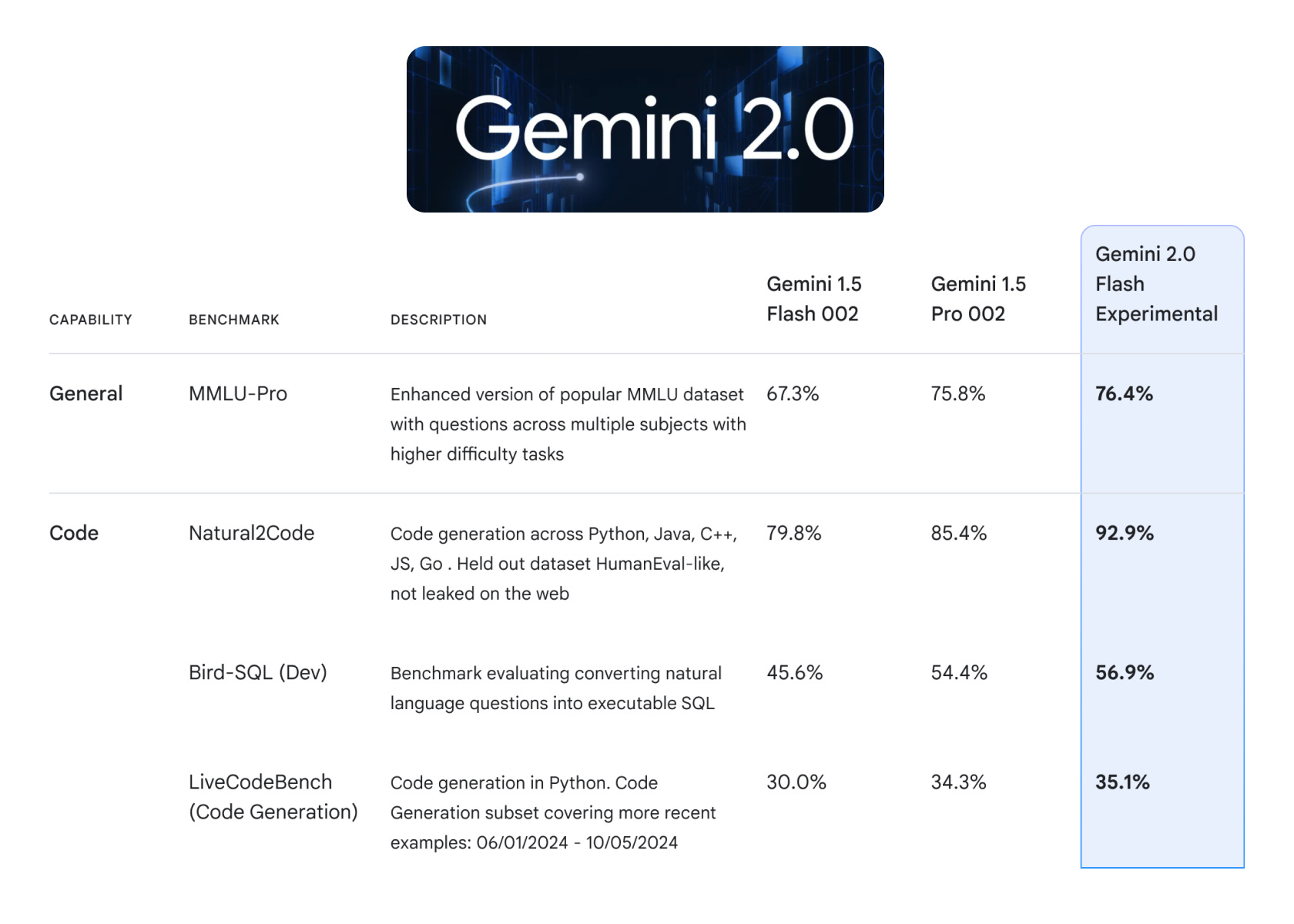
Google really outdid themselves with this release, not only does the model score exceptionally well on coding benchmarks versus Claude Sonnet 3.5 (new) but also does it ship with advanced agentic features like realtime voice + video input modes in the Live API. Google is now close to or depending on your POV leading in the AI race and it’s what people expected from the company since the open sourcing of TensorFlow. Especially notable is that they’re still completely unbeaten on video input and long context (up to 10M and 2M in prod).
OpenAI announces realtime video mode
Similar to Gemini Flash 2.0 realtime mode. Only Google got there first this time :) When access rolls out more broadly evals will likely show which of these does best (under which conditions). Tracking!
o1 pro mode scores high on reasoning tasks like PhD-Level Science Questions (GPQA Diamond), Competition Code (Codeforces), Competition Math (AIME 2024). It's pretty slow with a loading bar and has been described as "integrated best-of-n sampling" giving you sort of a pass@k level performance where k is something like 5 versus regular o1. Not sure if it warrants the $200 price tag associated to ChatGPT Pro Mode. Others have pointed out that $200 is maybe worth it for the increased o1 (non pro) rate limit increase. I guess it will be TBD how much traction the high price plan for ChatGPT will get.
DeepSeek releases update V2.5: 1210
Improved math & coding ability wrt original V2.5: MATH-500 benchmark increased from 74.8% to 82.8%. LiveCodebench (08.01 - 12.01) benchmark increased from 29.2% to 34.38%.
Microsoft releases Phi-4: 14B math buff
"Phi-4 outperforms much larger models, including Gemini Pro 1.5, on math competition problems". The technical report has been lauded for digging into the synthetic data generation strategies used. https://techcommunity.microsoft.com/blog/aiplatformblog/introducing-phi-4-microsoft%E2%80%99s-newest-small-language-model-specializing-in-comple/4357090 and unofficially on HF https://huggingface.co/matteogeniaccio/phi-4.
Snowflake releases strong permissively licensed multi-lingual embedding models: Arctic Embed 2.0
Very useful! Around the level of text-embedding-3 from OpenAI at 1/3rd of the dimension size.
Amazon releases Nova model series
Check out the technical report here https://www.amazon.science/publications/the-amazon-nova-family-of-models-technical-report-and-model-card. Their best model is approximately Llama 3.2 90B/Llama 3.1 70B level but Nova isn't open source. The report also highlights image generation and video generation models, showing that these models are presumably becoming table stakes technologies for large tech companies like Amazon/Google/Tencent/Alibaba/Meta etc.
$1M prize for beating a new SWE-bench like benchmark
Unreasonably high requirement (90%? open source only?). But interesting initiative to track SWE agent progress regardless.
DeepSeek-VL2: MoE A4.5B vision model competitive with Qwen 2-VL 7B/Pixtral 12B
Meaningful performance above Pixtral 12B at a much lower active param budget. Quite impressive.
Grok image generation model Aurora released
Grok 2 initially relied on FLUX for image generation on the X platform but now the team seems to be getting their image gen muscle on. Images are decent but not yet surpassing SOTA like Ideogram or FLUX1.1 [pro]. No API release as of yet.
Nous DisTrO: distributed model training
Nous has been making nice progress with distributed model training, one of the neat results is the DeMO paper which was co-authored with Diederik P. Kingma the author of the original Adam optimizer. DeMO shows controlled divergence can enable large scale distributed training. The Nous model doesn't have great MMLU scores that can compete with the slew of open source models available (all trained on fast interconnect clusters of course), but it's encouraging to see work in this area to guarantee we'll be less dependent on centralized training initiatives if we need to be in the future. In essence, this line of work is a nice hedge on centralization power. Which likely helps the centralized initiatives behave better as a result ;-)
Fish Audio 1.5 release: SOTA open source TTS
The gap between proprietary (ElevenLabs) and open source is shrinking. Try the playground at https://fish.audio/ it's very impressive. Check out the ranking of TTS models in the helpful HF leaderboard https://huggingface.co/spaces/TTS-AGI/TTS-Arena
📦 Repos
Flow Matching in PyTorch educational resource by Meta
"Flow matching is a recent framework for generative modeling that has achieved state-of-the-art performance across various domains, including image, video, audio, speech, and biological structures." for example, FLUX.1 is based on it as well as many other SOTA generative models in other multimodal domains.
HunyuanVideo: strong open source video model
There's also support for distributed inference using xDiT framework (xDiT: an Inference Engine for Diffusion Transformers (DiTs). Very cool work brining SOTA to local inference. A friend of mine is already generating videos with it on his 4090s!
Web Applets: An open spec & SDK for creating apps that agents can use
Really cool project by Rupert Manfredi incubated at Mozilla.
📄 Papers
Adam-mini: Use Fewer Learning Rates To Gain More
Reduced memory footprint version of the successful Adam optimizer. Awesome work for hobbyist fine-tuning that typically try to squeeze the most out of their hardware. Support seems to have already landed in LLaMA-Factory https://github.com/hiyouga/LLaMA-Factory
🦣 MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
"Using only open models, we create a dataset containing 12M instruction-response pairs to cover diverse, reasoning-intensive tasks with detailed and faithful rationales." nice study that shows that post-training for reasoning in the vision domain has lots of potential. They set SOTA scores on vision reasoning tasks like MMMU-Pro (+7%).
Byte Latent Transformer: Patches Scale Better Than Tokens
Meta frees us from the burden of tokenizers, at last. "We present the first flop controlled scaling study of byte-level models up to 8B parameters and 4T training bytes." and "Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it." Meta truly GOAT, this is phenomenal.
Attamba: Attending To Multi-Token States
Compressing tokens to avoid "quadratic scaling of compute with sequence length", clever approach and quality hit seems minimal.
They explore finetuning on O1 API data (against ToS, but hey, science!) and remark on the importance of not relying (solely) on distillation for achieving SOTA on open models.
Training Large Language Models to Reason in a Continuous Latent Space
"By delaying definite decisions and expanding the latent reasoning process, the model pushes its exploration closer to the search tree’s terminal states, making it easier to distinguish correct nodes from incorrect ones."
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
Of course the answer is yes, but the paper highlights in a helpful way that it's only the case for certain types of queries. Shortcut exploitation is a notorious issue with machine learning models and undermines generalization ability of models.
PaliGemma 2: A Family of Versatile VLMs for Transfer
They highlight how their models can be used for transfer-learning to domain specific tasks like "table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation".
JetFormer: An Autoregressive Generative Model of Raw Images and Text
"... most of these models still rely on many separately trained components such as modality-specific encoders and decoders. In this work, we further streamline joint generative modeling of images and text. We propose an autoregressive decoder-only transformer - JetFormer - which is trained to directly maximize the likelihood of raw data, without relying on any separately pretrained components, and can understand and generate both text and images." I like approaches that are aligned with the Bitter Lesson https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling
This training-free sampling guidance method meaningfully boosts the quality of the generated videos. Magical.
The broader spectrum of in-context learning
This paper by folks from Google DeepMind places the phenomenon of in-context learning in a broader context of research on generalization and meta learning. Helpful if you're interested in learning more about in-context learning and how it will develop over the next years of AI research.
🛠️ Products
GitHub now has a chat feature that supposedly integrates with GitHub data (through GitHub APIs) well. My test queries didn't fare very well, let me know in the comments if you have more success!
Luma Labs releases image generation model Photon
Competitive with other SOTA. Not open source. Stunning images, but fails my "a coffee cup upside down on a table" prompt adherence test. Oh well, more work to be done I guess :)
Repo Prompt: codebase to prompt
Utility to generate prompts from your codebase. Handy for models like O1 Pro Mode that don't have APIs yet. A handy crutch for the gap between those models having APIs (at which point the Repo Prompt utilities will just be handled by Cursor/Windsurf AI-first coding IDEs).
Serper: Google SERP search for LLMs
Came across this while looking at the Arena Agent leaderboard (cool project by Gorilla, see link in this newsletter). https://www.agent-arena.com/leaderboard
📚 Resources
The Future of Math with o1 Reasoning with Terence Tao and Mark Chen (SVP of Research @ OpenAI)
As one commenter suggests, the TLDR is "in the short run will help mathematicians develop proofs, but in the long run probably replace humans entirely."
Agent Arena: a leaderboard for agentic tasks
Cool project by the Gorilla team. LMSYS style leaderboard on agentic tasks like search, stock/financial data manipulation, research, automation.
A failed experiment: Infini-Attention, and why we should keep trying?
Good to see these kinds of write-ups, they are often more educational then just sharing a successful attempt.
AI safety benchmark AILuminate by MLCommons
Useful resource to get a quick safety score for models.
NeurIPS talk by Ilya Sutskever
"Pretraining is dead, long live compute"
Reward Hacking in Reinforcement Learning
As mentioned earlier in this newsletter, models are susceptible to taking reasoning shortcuts (as explored in the multi-hop reasoning scenario). Lilian Weng always does a phenomenal job writing up ideas in ML and this blog post is no exception. This post dives mainly in the problem of reward hacking while a promised future post will go into mitigations. Lilian has actually just recently left OpenAI so maybe she's a bit more free to discuss these ideas moving forward. Tracking!
Surprisingly informed and grounded review of Sora from the perspective of actual users (not academics). Watch this is you don't have Sora access (they stopped accepting signups).
List of interesting LLM benchmarks by Ir. Thomas
For example, it tracks benchmarks where humans still hold the record vs SOTA AI. That list might shrink faster than we'd like haha!
Scaling Automatic Neuron Description
Cool work scaling mechanistic interpretability by describing neurons of Llama-3.1-8B-Instruct. They release a dataset with descriptions of every neuron in the model!
Tutorial on Inference Time Compute by a 3rd year PhD student from UChicago.
Want more? Follow me on X! @ricklamers