
Gemini 2.5: Google on top after 5 years of playing catch-up
Week 13 of Coding with Intelligence

Woops! Something went wrong with the links in the previous email. Should be fixed now!
📰 News
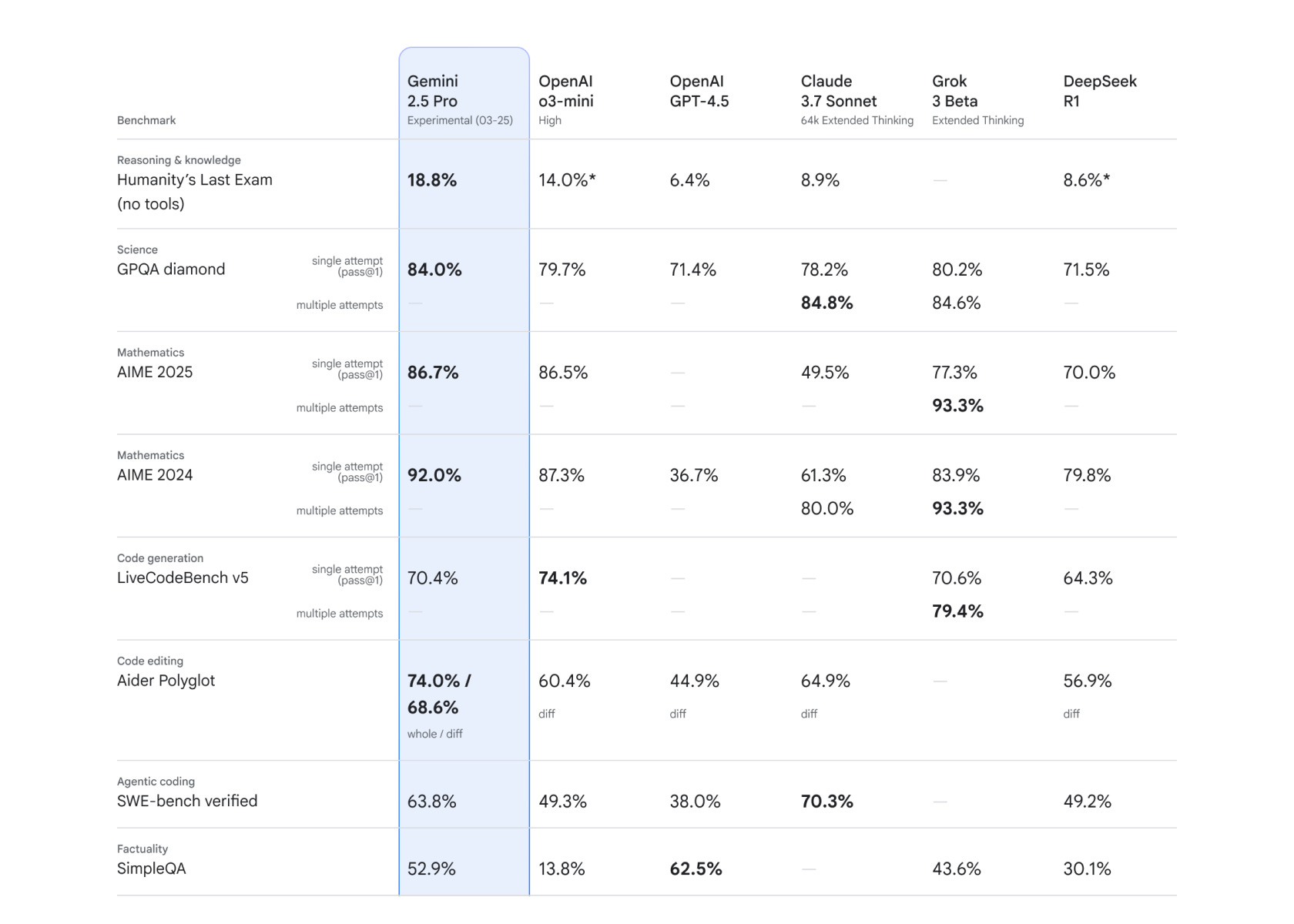
Gemini 2.5: Our most intelligent AI model
It's a reasoning model. It leads models like Claude Sonnet 3.7 thinking on benchmarks like https://livebench.ai/. Vibe checks by r/LocalLLaMA are coming in very positive as people report Gemini 2.5 Pro fixing their Claude Sonnet 3.7 generated code.
The very large context window support Gemini is known for (1M) can further enhance this capability increase, as for practical in-IDE code generation being able to easily include large amounts of context significantly enhances real-world usability. I expect a massive amount of demand for this model. A lot of pressure already on Google to increase rate limits.
Gemini 2.5 also scores really well on the proprietary tool use benchmark from Scale AI which is an important measure for building agents with these models. Cursor / Windsurf both shipped support for Gemini 2.5.The long awaited image generation capabilities of GPT-4o finally dropped and the world took notice in the form of Ghibli-style images. Marketing as a field in particular and many many niche-focused image generation startups are going to find themselves unable to compete. See for example image generations like this that incorporate provided product images extremely well.
This release is noteworthy for another reason, which is that it seems more and more true that ChatGPT invests deeply in their consumer ChatGPT app and is winning the fight with Anthropic on that front. Anthropic however currently has the best model for code assistance in IDEs like Cursor/Windsurf/Claude Code (CLI). I suspect this image generation release is going to exacerbate ChatGPT's lead in being the go-to consumer app for anything AI across the worl.o1-pro now available via the API at extreme prices
o1-pro, available to ChatGPT Pro users only prior to this release, is now available on the OpenAI API for $600 (!) per 1M output tokens and $150 per 1M input tokens.
The pricing was not well received and if you've used the ChatGPT app you know that o1-pro can take a lot of time to respond. I guess we now know approximately the upper bound of what the market is interested in consuming in terms of cost/time per unit of intelligence.
What of course matters is that o1-pro has a fairly limited incremental intelligence advantage compared to Gemini 2.5 Pro, Claude 3.7 Thinking or even models like R1. Hence the appetite for this endpoint seems low.ARC AGI 2: a new benchmark for AI reasoning capabilities
Their benchmark focuses on measuring the ability of language models to adapt to novel, never-before-seen tasks. In addition, they emphasize tasks where regular humans are relatively easily capable of solving them.
Novel about ARC-AGI 2 is that they've conducted their own study with 400 people participating to verify that their new benchmark meets this criteria. ARC-AGI 1 has been "solved" by frontier models through scaling up test time inference. For more details about the performance of frontier models on ARC-AGI 1 see the blog post.
This benchmark is important since it can accelerate the timeline to stronger more useful LLMs that make fewer mistakes, e.g. hallucinate less. Benchmarks are impactful because popular evals inherently lead to hill climbing by various labs/groups that are in competition to top the leaderboard. If the benchmark is strong, e.g. not susceptible to shortcuts/cheating, then the models that end up performing will end up having high utility for real-world use cases.OpenAI launches new TTS models
The voices don't sound like SOTA voices like from e.g. ElevenLabs/Cartesia. I guess they were too focused on other areas to ship a new SOTA result here. I will add that pronunciation is very accurate. The more noteworthy update is content based Voice Activate Detection (VAD) which means that it won't speak over you as frequently (available in the OpenAI Realtime API).
A nice contribution from Qwen in the category of open source vision language models. See Simon Willison's blog post for a quick preview of its abilities. It's permissively licensed with Apache 2.0.
OpenAI announces MCP support in OpenAI Agents SDK
This was accompanied by a Tweet from Sam Altman where he announces that MCP will be supported in the ChatGPT desktop app and on the Responses API. This will definitely lead to an explosion in MCP-related activity and to it becoming the dominant "agent standard" for distributed tool calling and all the other MCP server capabilities (like MCP servers being clients to other MCP servers, resources).
New Model Context Protocol (MCP) spec released
In summary the new spec introduces: OAuth 2.1, Streamable HTTP, JSON-RPC batching, and tool annotations. See this link for tool annotations, it offers additional ability to clarify properties of tools when defining them. For example, whether they're idempotent (calling more than once doesn't have an effect, like approving a transaction), or that an operation is read-only.
Basically, this article by Anthropic shows how 'circuit tracing' lets us peek inside LLMs like Claude Haiku to see how they really do things like reason, plan poems, or handle multiple languages, and can even spot the hidden mechanisms behind refusals, hallucinations, or faked chain-of-thought.
Great work for alignment & improvement of LLMs as they continue to become more entrenched in everyone's day-to-day workflow/lives.Groq launches PlayHT TTS model endpoints
Cool release by Groq, we can now do fast TTS 🙌 I personally like the Gail and Celeste voices.
📦 Repos
mcptools: A command-line interface for interacting with MCP (Model Context Protocol) servers
Neat project to interact with MCP servers.
📄 Papers
Video-T1: Test-Time Scaling for Video Generation
Interesting to see increased test-time-compute generalizing to domains like video generation. Impressive generated videos as a result.
Cohere details Command A model including training process
Interesting deep-dive from a lab that creates enterprise focused proprietary models (and some open weight models). Noteworthy is their use of model merging. I get particularly excited about their up-to-date BFCL focused (that's a leaderboard for function calling) evaluation for agentic use cases. Remember, agents are just function calls in a while loop ;-).
Measuring AI Ability to Complete Long Tasks
Most predictions about how strong AI models will be in the future are very hand wavy "my gut is telling me this"-style answers. This paper from the Model Evaluation & Threat Research (METR) institute (co-founded by ex-DeepMind, ex-OpenAI researcher) is more rigorous and their estimates indicate that software development tasks that currently take humans months might be able to be fully automated by AI systems in 5 years from now. And in 3 years from now fully automated software tasks that now take a human an entire day.
Which, looking at the rate of progress in code generation models (Claude Sonnet 3.5 > 3.7 > Gemini 2.5) does not feel entirely unrealistic.Reasoning to Learn from Latent Thoughts
Interesting paper from researchers at Stanford, University of Toronto and Vector Institute. They observe that directly pre-training on outputs (e.g. published content on the web) ignores the reasoning process (latent thoughts) that happens before someone writes their final answer down. They find that by inferring latent thoughts (see paper for details on how they do that) they can increase the learning efficiency of models.
🛠️ Products
Docent: LLM powered agent observability tool
With agents generating many many traces that are too time consuming to manually evaluate we need a new solution. Docent suggests an approach powered by LLMs, I like their direction a lot. I recommend everyone building agents and agent evals to take a closer look. I'm not affiliated with the company whatsoever.
📚 Resources
Stanford CS224N NLP course by Professor Christopher Manning
This is a high quality course by the legendary Christopher Manning. His work on GloVe word vectors are attributed to be an early formulation of the attention mechanism used by transformers. Dated April 2024 so should be fairly up-to-date as these courses tend to focus on fundamentals that move slower than the model-du-jour.
More & more MCP registries popping up, I've been "catching them all" so here's my current list for you:
https://smithery.ai/
https://www.mcp.run/
https://glama.ai/mcp/servers
https://www.pulsemcp.com/
https://opentools.com/registry
https://github.com/modelcontextprotocol/servers
https://mcp.composio.dev/
https://github.com/michaellatman/mcp-get
https://mcpserver.cloud/
https://github.com/cline/mcp-marketplace
http://mcpservers.com/
https://www.mcpt.com/
Note that an official registry is slated for launch.Cloudflare ships remote MCP Server support
Neat SDK for deploying remote MCP servers, their playground even has the ability to plug in your
/sseMCP URL to try it out. Noteworthy is their strong focus on authentication concerns which of course is more important when an MCP server is remote.Roaming RAG – RAG without the Vector Database
Interesting trend, with agents become more capable due to increased function calling capabilities of newer models, it becomes more common for agents to fetch needed context dynamically as the agent progresses. This is very similar to Model Context Protocol which seems to have launched with more focus on dynamically fetching context through tools rather than action taking through tools. Although the latter now definitely seems to have an equal amount of focus for the MCP protocol (e.g. with code generation).
Want more? Follow me on X! @ricklamers