
Going deep on Reasoning + Agents
Week 26 of Coding with Intelligence

📰 News
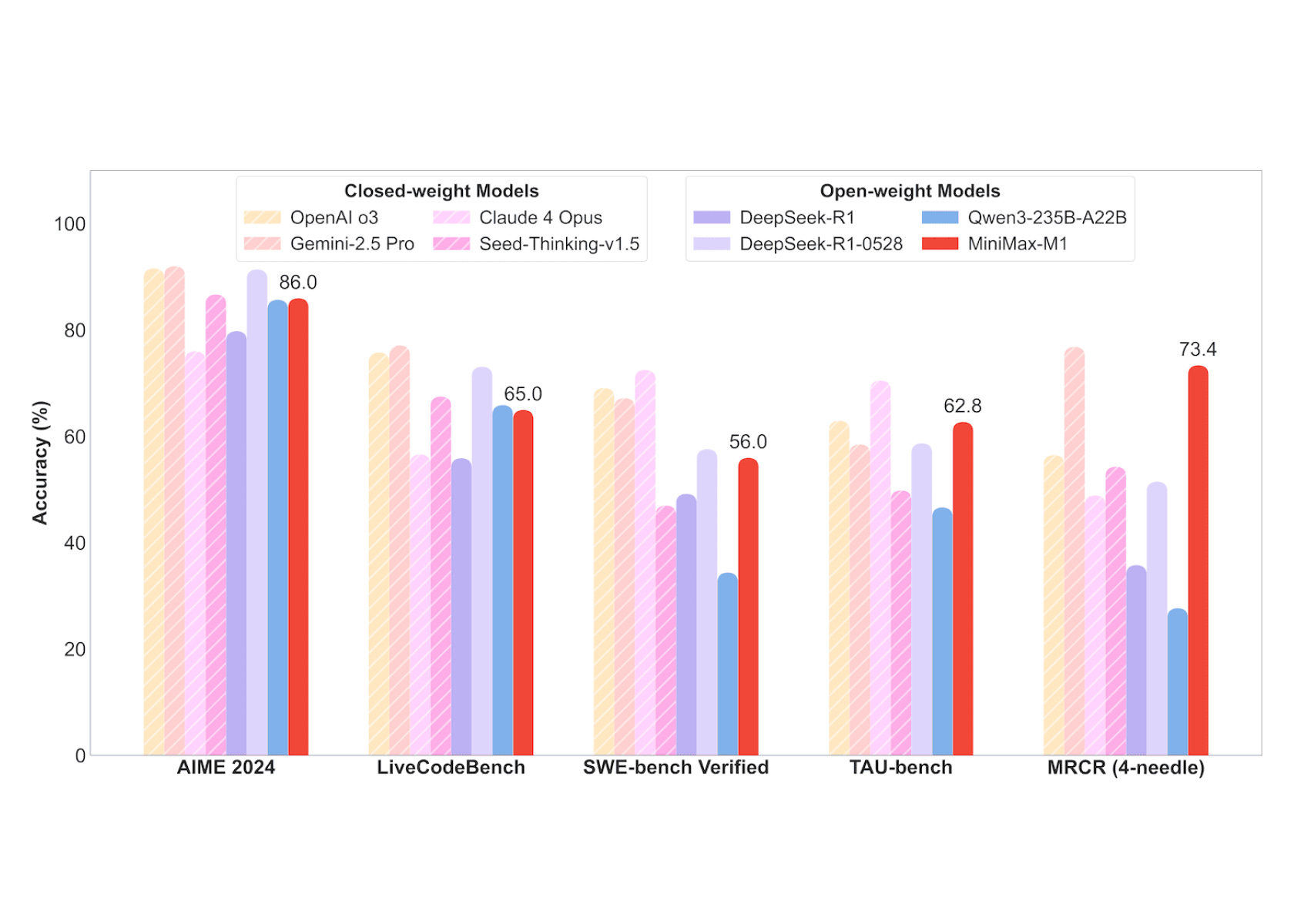
MiniMax releases two strong open LLM
A very interesting release that you shouldn't ignore. Noteworthy for truly competitive SOTA performance across tasks (range of Claude 4, Qwen 3 235B MoE, R1 0528) with a hybrid attention mechanism + reasoning for scaling more efficiently to longer context. Paper and Hugging Face models are also available, all linked to from the GitHub repo. They use Lightning Attention for their linear-scaling attention portion combined with traditional softmax attention. True open-weight with Apache 2.0.
Mistral releases their first reasoning model: Magistral
They release a 24B open source small variant called Magistral Small and a Magistral Medium version that's only available on their API. In terms of quality the Medium model benchmarks close to R1. R1-0528 is probably a bit better though and API pricing of Magistral Medium at $2 and $5 for input/output respectively clocks quite a bit higher than R1-0528 pricing for most providers.
The release is accompanied by a decent 24-page paper, along with the open weight Magistral Small model we can definitively say that Mistral is keeping open source from EU soil alive https://arxiv.org/abs/2506.10910ByteDance's latest video model: Seedance 1.0
Very impressive video generation. Seems to lead Veo 3 in certain categories like realistic human aerobic movement. But doesn't have audio-generation built-in like Veo 3 does.
Takes the #1 spot on the Artificial Analysis' video generation leaderboard.
https://artificialanalysis.ai/text-to-video/arena?tab=leaderboardHailuo 02: latest video generation model by MiniMax
Impressive video generation, leading SOTA with Veo 3 and Seedance 1.0
Kyutai STT: A speech-to-text model architecture optimized for real-time usage
You might have seen Kyutai's previous release which felt a bit mediocre but I think they really one upped themselves here. The demo on https://unmute.sh/ felt quite compelling with strong semantic voice activity detection making the conversation feel natural. Something I definitely can't say I feel when talking to Siri.
POLARIS: A POst-training recipe for scaling reinforcement Learning on Advanced ReasonIng modelS
A cool release of a 4B and 7B model and a great deep-dive post going into the details of scaling RL for reasoning with small models.
They dropped models on the Hub https://huggingface.co/POLARIS-Project/models
Haha no those capitalizations aren't typos, they spell POLARIS.New details from Qwen team about Qwen3 & roadmap
The Qwen team views MoE as the future architecture and is currently developing Qwen 3 coder models while believing pretraining can be significantly optimized through RL integration, better data cleaning, and synthetic data addition. Their roadmap includes scaling RL for long-horizon agent tasks in post-training, expanding context length from 1 million tokens this year (for almost all their models) to 10 million later, and developing computer-use agents with enhanced vision capabilities alongside planned image and video generation capabilities for their omni models.
Qwen3 releases embedding models
Qwen3 Embedding: 0.6B-8B models, 70.58 MTEB score (No.1 in the MTEB multilingual), 100+ languages, Apache 2.0.
📦 Repos
OpenCode: Claude Code alternative by SST
Clever move by SST which builds a Terraform-esque product to easily manage infrastructure needed for your code/apps. I think this dovetails nicely with the trend that Karpathy has described when he speaks about the pains of vibe coding of needing to do a lot of manual in-browser. Read Andrej Karpathy's story about that here https://karpathy.bearblog.dev/vibe-coding-menugen/ or check out his YC AI Startup School talk where he touches on the same concept https://www.youtube.com/watch?v=LCEmiRjPEtQ
Cool project improving vLLMs KV caching abilities.
📄 Papers
Meta Topic: Test-Time-Training
There is something "in the air" it feels like where more & more parties are exploring the idea of Test-Time-Training more seriously. It's the concept that the model evolves and adapts "online" in the classical online-learning ML sense. There are practical limitations and considerations but it does help us move away from these static blobs that have these hard cutoff dates and can't easily be updated to get right what they currently get wrong.
Dynamic Deep Learning proposal by the author of the Bitter Lesson, Rich Sutton (main link), Pathways idea from Jeff Dean
The other papers linked explore similar ideas so consider it to be like a paper reading list on the topic.ATLAS: Learning to Optimally Memorize the Context at Test Time
See Meta Topic: Test-Time-Training
See Meta Topic: Test-Time-Training
Titans: Learning to Memorize at Test Time
See Meta Topic: Test-Time-Training
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
See Meta Topic: Test-Time-Training
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
See Meta Topic: Test-Time-Training
An alternative to quadratic full attention and linear SSM based attention. Co-authored by the original author of Mamba, Tri Dao.
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
An investigation by NVIDIA of how prolonged RL (scaled RL) can truly expand beyond the capabilities of base models (even if those are repeatedly sampled).
RewardAnything: Generalizable Principle-Following Reward Models
Cool research project with extensive evals on reward models with a usable Python SDK to try out the reward model they've released.
ResearchCodeBench: Benchmarking LLMs on Implementing Novel Machine Learning Research Code
With LLMs getting better at code generation they will be utilized more for writing code to support research activities. This research quantifies how well current SOTA models like o3, Gemini 2.5 Pro, o4-mini, etc perform at implementing research code for novel ML ideas faithfully. The bench isn't saturated but promising results are achieved nonetheless. TLDR Gemini leads the pack.
Sharpening or Discovery, RL or Meta RL?: How RL Improves LLM Reasoning
Two researchers at CMU explore whether RL simply brings to the foreground existing capabilities of models or whether RL actually generates new capabilities within LLMs.
The authors conclude that RL can either merely "sharpen" existing model capabilities or genuinely "discover" new reasoning strategies, with the key difference being whether RL learns to systematically chain basic skills (meta-RL) versus just reinforcing successful individual responses.Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
Really cool work exploring how natural parallelism in thought can be used to speed up generation.
Reinforcement Learning Teachers of Test Time Scaling
Interesting idea to use strong models to fill in the path from Question to Answer and allow that to let weaker models "hillclimb" the right solution path.
Includes a code release https://github.com/SakanaAI/RLTThe Qwen 3 team already highlighted their focus of exploring the use of RL in pre-training, this paper by Microsoft Research and researchers from Tsinghua and Peking University proposes a practical training setup and attempts to characterize scaling behavior using small scale models.
LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Not open source, but ContextualAI did release a paper. Very interesting to combine promptable reward models like this with RL training toolkits like verifiers (https://github.com/willccbb/verifiers). LMUnit is available through their API. They rank #1 on the https://huggingface.co/spaces/allenai/reward-bench leaderboard.
An exploration by the Qwen team of LLM reasoning mechanisms.
📱 Demos
Google releases Magenta Realtime audio streaming model
A really neat release with impressive open-ended jamming capabilities! Check out the videos!
🛠️ Products
Mistral Code: VS Code/JetBrains extension
Seems to be enterprise-license only unfortunately, I wish they would allow you to just plug-in an API key. Seems like they are using this to monetize enterprise customers in the EU who care a lot about code/IP-leakage risks and data sovereignty.
📚 Resources
Extending AFM-4.5B to 64k Context Length
Interesting deep dive into how to extend the context window of models.
Cognition, company behind Devin SWE agent, releases Blockdiff: an efficient VM disk snapshotter
Cool to see companies continuing the trend of releasing open source infra components (e.g. k8s) to enable other companies contribute and strengthen low level building blocks for building better software. This release in particular is interesting as SWE agents and other kinds of computer use agents need isolated environments from a safety/repeatability perspective and inefficiencies around that really add up when you're running potentially hundreds of agents in parallel per user.
How Anthropic built their multi agent research agent and what they learned from it
TLDR naturally parallelizable tasks can benefit from multi agent setups but at the cost of increased token consumption. Design your prompts & tools well for robust performance. Deployment is still tricky and has footguns when scaling.
PR Arena: observe background SWE agents stats in realtime
Very cool to have a quantitive longitudinal view on how well various agents are performing.
Neat resource if you want to learn more about the nuts and bolts of GPU programming
[Video] Anthropic Interpretability lead interview on LLM Circuits
Deep dive into the use of Interpretability work in AI with Emmanuel Ameisen from Anthropic. I like how they dig into tutorial materials Anthropic recently released to spur open source activity around interpretability. They also showcase the Neuronpedia Circuit Tracer tool which allows you to explore LLM circuits.
[Video] SFT training Qwen3-4B for MCP web-tool use by Ronan McGovern from Trelis Research
This is an awesome workshop done by Ronan McGovern, very densely packed 35 minutes of content to get your feet wet with SFT training smaller models by distilling agent traces from stronger counterparts (in the video he used the stronger Qwen3 30BA3B model).
[Video] Latent Space podcast interview with OpenAI reasoning lead Noam Brown
In their words the interview covers "The Bitter Lesson vs Agent Harnesses & World Models, Debating RL+Reasoning with Ilya, what's *wrong* with the System 1/2 analogy, and the challenges of Test-Time Scaling"
Recorded at the recent AI Engineer in June in SF, Dylan characterizes China's position when it comes to compute and explains nicely some of the tactical steps they've taken to strengthen their position (e.g. stockpiling HBM chips through shell companies). An interesting peek into the global race of AI infrastructure.
Want more? Follow me on X! @ricklamers