
Open Source o1 has (almost) arrived: DeepSeek R1-Lite-Preview
Week 47 of Coding with Intelligence

📰 News
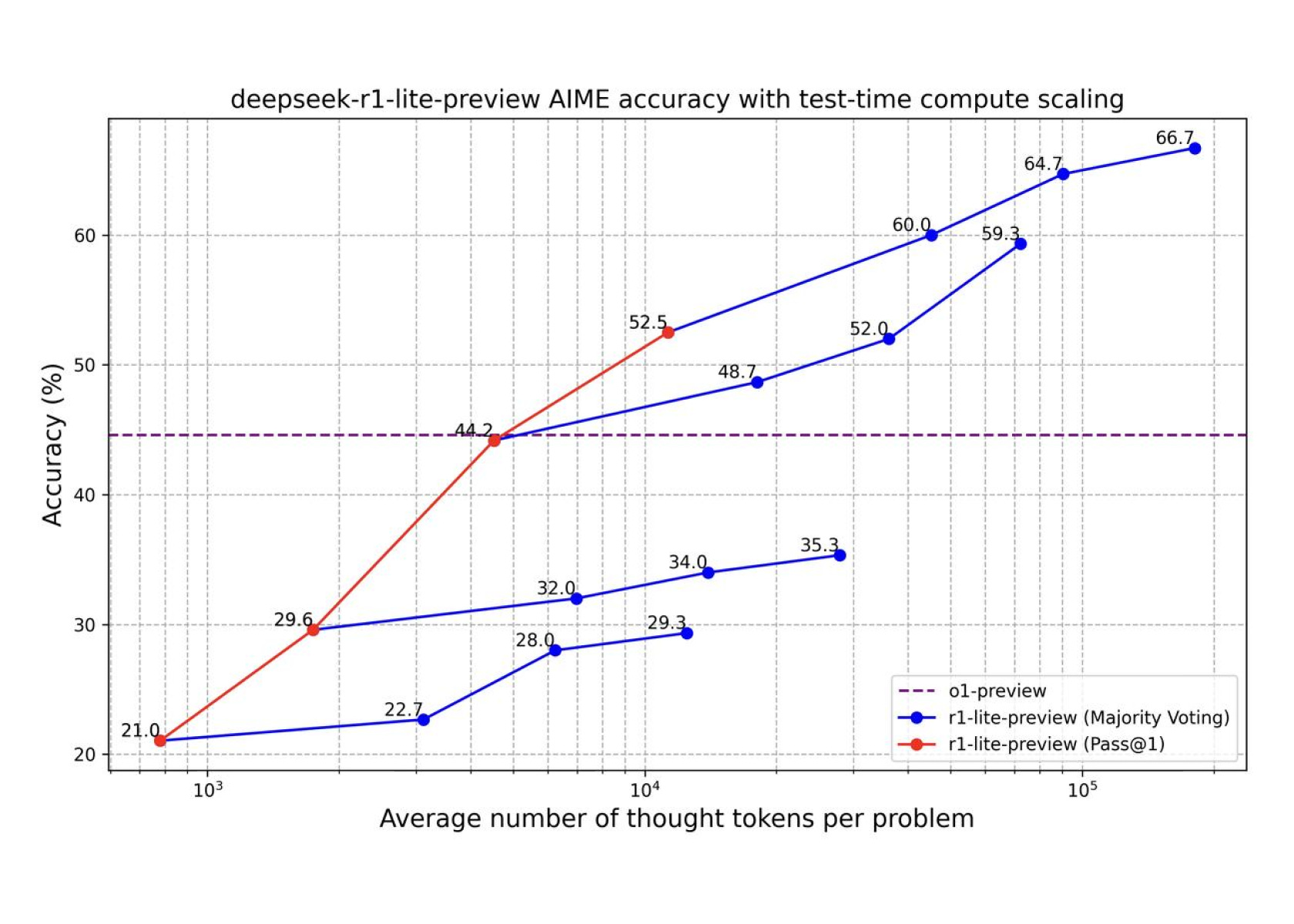
DeepSeek-R1-Lite-Preview: o1-preview-level performance on AIME & MATH benchmarks
Awesome to see that moats aren't very long lived. DeepSeek promised to open source this model too, hasn't dropped yet but I'm sure the community is anxiously waiting.
XGrammar: new Structured Generation library by the MLC project
The repo: https://github.com/mlc-ai/xgrammar
step-2-16k-202411: a mysterious 1T model just appeared
Livebench.ai is a neat benchmarking attempt that constantly updates to avoid being saturated by Training On the Test Set. step-2-16k-202411 ranked just below o1-mini and above last week's entrant gemini-exp-1114. Although 1T seems prohibitively expensive to run. Reportedly Claude Opus 3.5 isn't being deployed for the exact reason of the economics of the scale of the model not weighing up against the performance delta versus other (smaller models) like Claude Sonnet 3.5.
It performs well, from the blog: outperforming all of Claude-3.5 Sonnet (new). Unfortunately, only available under non-commercial research license. Great work though from the folks at Mistral, and kudos for an open weights release!
Qwen2.5-Turbo: 1M long-context Qwen
Impressive performance and evals (NIAH, RULER and LV-Eval). Congrats team Qwen! It's not released as a model/inference setup though, API only.
CoT fine-tuning, MCTS for search. First impression this doesn't look very good. At least on the small model they performed these steps on it's only marginally better than Qwen 2 7B.
Want to also make one remark about Google DeepMind folks dropping another model, the gemini-exp-1121 model, which purportedly is even better than gemini-exp-1114, YMMV but whatever the case, I’m glad labs are making improved models available more quickly to end users!
📦 Repos
LTX-Video: more open source generative video models
Impressive model by an impressive team. I'd give this a look if you care about generative video models/inference.
Reasoning for multimodal models. Like Insight-V from this week's roundup.
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Microsoft drops the official implementation for very-low-bit LLMs and it's fairly efficient! Paper accompanying the software release https://arxiv.org/abs/2410.16144 and the original BitNet paper https://arxiv.org/abs/2402.17764
Tülu 3: open model + code for SOTA post-training
Specifically their Reinforcement Learning with Verifiable Rewards (RLVR) treatment is worth taking a look at. Awesome work by the folks at Ai2.
AIMv2: vision encoders by Apple
Awesome follow-up work by Apple. Autoregressive Pre-training of Large Vision Encoders, see https://github.com/apple/ml-aim also.
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models
Paper + Code + Checkpoints. With o1 being text only it's great to see the next frontier is rapidly being explored: multimodal reasoning chains. Should help a lot with embedded AI like robotics.
📄 Papers
BALROG: Benchmarking Agentic LLM/VLM Reasoning On Games
The Return of Games for benchmarking. Pre-ChatGPT/GPT-3 using games to benchmark AI was all the rage with Lee Sedol's famous Go match and OpenAI beating pro humans in Dota 2 and of course the famous Atari benchmarks. We'll see how things go when using games to evaluate LLMs. Signal or noise? The current leaderboard seems to decently rank models although in the top ranks it's not clear whether the ranking is really definitive (Llama 3.1 < GPT-4o-mini? Llama-3.1-70B-it > Llama-3.2-90B-it?).
What Do Learning Dynamics Reveal About Generalization in LLM Reasoning?
"begin to copy the exact reasoning steps from the training set" a useful observation that can lead to higher quality pre-training by focusing on including general reasoning patterns in the pre-training corpus. Or even steering towards these in post-training to eliminate flawed non-general reasoning patterns.
DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging
"improves the perplexity of the model without increasing its size ... an additional averaging step after each transformer block ... coherent patterns of information flow, revealing the strong and structured reuse of activations from distant layers" looks like carrying information forward is important. Will be interesting to see if this "architecture trick" is adopted by open source model providers. Of course, proprietary labs might already know of this and use it (or similar) in their models.
📱 Demos
Neat chat playground to try out the Tülu3 model
MagicQuil: An Intelligent Interactive Image Editing System
Very cool project, not open source, but they do have a demo up.
A neat narrow-focus image model by folks from 🤗 Does what it says on the tin!
🛠️ Products
Interesting idea of branching agents through snapshotted VMs. Potentially powerful in the new search oriented inference-time compute scaling that labs are exploring. Private preview unfortunately it seems.
📚 Resources
AI eats the world by Benedict Evans
A thought piece by Benedict Evans ex-a16z partner on where AI is going. A nontechnical more market focused lens I think provides a helpful view on what practitioners, even those operating at the detailed technology level, can expect over the next few years. Although "It will work like every other platforms shift" <> "No-one knows" does more likely than not leave figuring out the actual answers as an exercise to the reader.
Say What You Mean: A Response to 'Let Me Speak Freely'
Outlines authors publish a rebuttal on https://arxiv.org/abs/2408.02442 TLDR with precise handling structured output _does_ improve performance.
Example prompt from Yann LeCun for reasoning models
DeepSeek-R1-Lite-Preview cracks it!
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
Interesting paper highlighting how reasoning is influenced by pretraining in LLMs.
Want more? Follow me on X! @ricklamers