
Open Source RL training landscape grows
Week 19 of Coding with Intelligence

📰 News
Zyphra Zonos: strong open source tts model with voice cloning
Especially their voice cloning examples are highly impressive (stay safe with these audio deepfakes!). Noteworthy that they have both a Transformer and a SSM-hybrid version. The weights on HF are licensed Apache 2.0
They claim:
>significantly improved capabilities for coding, especially building compelling interactive web apps
Reports on 0506 vs the previous 0325 version of Gemini 2.5 Pro vary. What is a bit unfortunate is that the 0325 version is no longer available as that now redirects to the 0506 model.OpenAI opens up broader access to Reinforcement Tuning API
You can train o4-mini, define custom grader models, see training data + integrated evals, and of course, run inference on the trained models.
Mistral launches Mistral Medium 3
Numbers look roughly on-par with GPT-4o, although it's not available for download (this is a non-open-weight release).
Model Context Protocol merges support for tool output schemas
I personally really like this, it's always been surprising to me that no type enforcement is baked into the tool calling/function calling protocol pioneered by OpenAI. It seems now that MCP is taking the lead to standardize not just tool input schemas but also output schemas to simplify predictable data flows in tool augmented LLMs. These motivations especially resonate with me:
> Transforming tool results before forwarding content to the model (e.g. formatting, projecting).
> Making tool results available as structured data in coding environments.
📦 Repos
RAGEN: train LLM reasoning agents in interactive, stochastic environments
Really cool research project for training reasoning agents in interactive environments, built on top of veRL (see a pattern?) by an ex DeepSeek researcher. Projects like verifiers of Will Brown, who has recently moved to Prime Intellect, are getting more common and popular.
logitloom: explore token trajectory trees on instruct and base models
This is a cool visualization of the assigned probabilities to various token completions in tree form. Check it out if you want to peek into the model's brain (and potentially understand in which way it's misunderstanding your prompt intent).
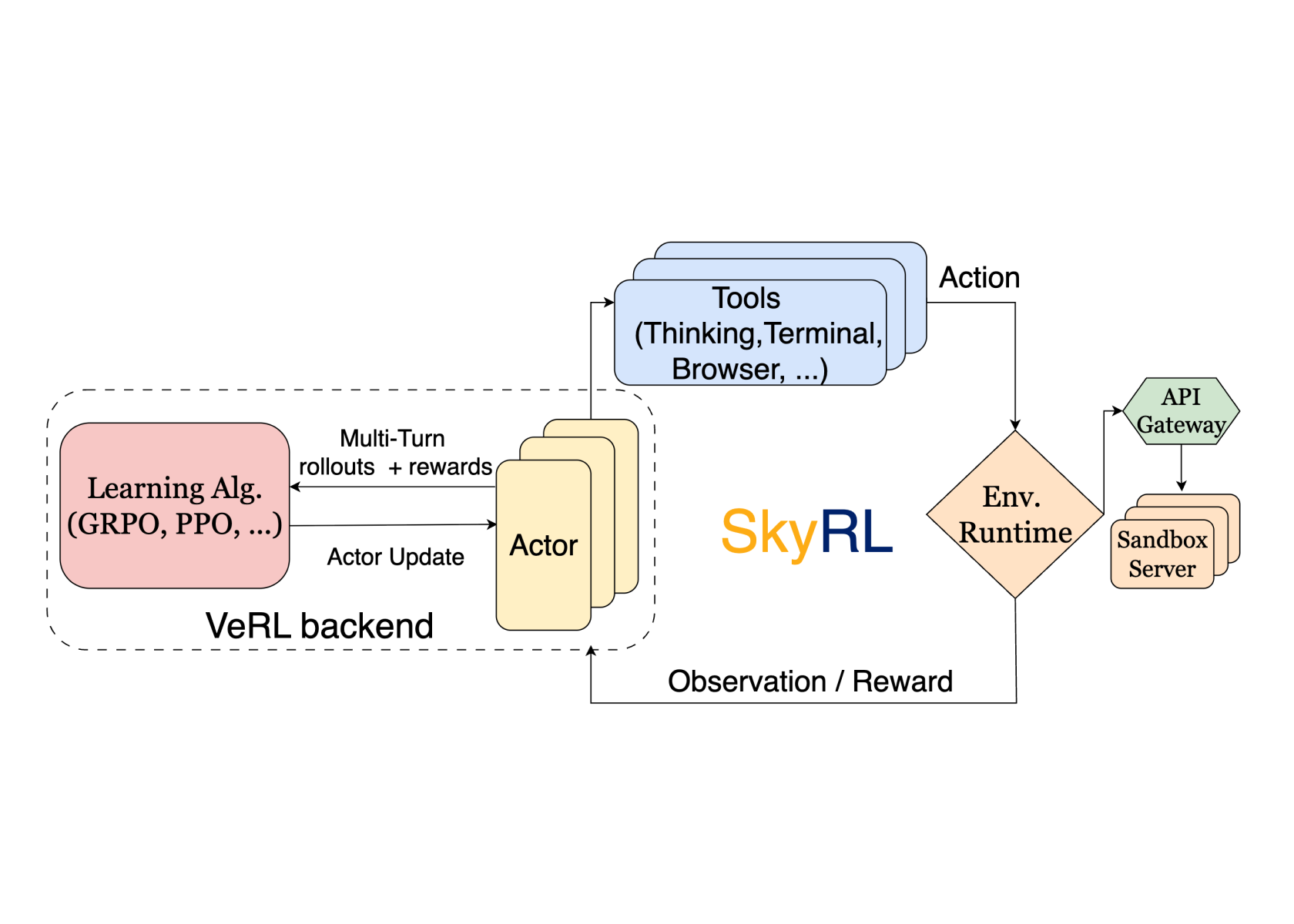
SkyRL-v0: a long-horizon RL training framework
Awesome project by folks from Berkeley, Anyscale, All Hands AI (creators of the SWE agent Open Hands). In addition to a training framework they release model snapshots that have been trained with the framework. The project builds on the foundation of veRL which is a mature industrial RL training stack maintained by ByteDance.
SWE-smith: a data generation pipeline for synthetic task construction
A cool project from the folks that launched SWE-bench (a pretty canonical benchmark for evaluating model's ability to assist with end-to-end software development). This project does not just lead to better evals (on less contaminated/static data) but also can be used for training RL-style (see SkyRL in this newsletter).
scenario: agent testing library that uses an agent to test your agent
I found this because of create-agent-app, this is a neat library to easily test agents without having to manually vibe check them. The focus on the terminal as an interface and feeling like an extension of a native unit testing framework make this a pretty cool project imo.
create-agent-app: 1 agent in 9 frameworks
Cool comparison project to see how you'd define the same agent in 9 different frameworks (including a no-framework example). The author told me he likes LangGraph (functional style) and Agno most!
Agno: surprisingly clean agent coding framework
I like how their code seems to be reduced to the absolute least amount of Python code for common sense agent definitions. It also ships native support for MCP servers for tool execution.
Astral's Python type FAST checker in Rust: ty
You may know Astral from
ruff/uvfame.ty, being focused on speed, is very useful for SWE agents that operate on type issue feedback in a fast loop before presenting their work to the developer. This relevance to AI is why I included it this week. Astral is the GOAT.
📄 Papers
Type-Constrained Code Generation with Language Models
Interesting extension of constrained decoding by researchers from ETH and Berkeley. Typically constrained decoding is limited to JSON or JSON Schema. They propose a technique for adhering to complex typed code. They show even strong large open source models like Qwen2.5 32B benefit significantly on benchmarks like HumanEval and MBPP.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
This paper shows that we have surprisingly little understanding in how RL-based LLM training contributes to improved performance on various tasks. Interesting result to analyze.
On the generalization of language models from in-context learning and finetuning: a controlled study
Interesting theory paper from Google DeepMind about the difference between generalization between finetuning and in-context learning.
Visual imitation enables contextual humanoid control
From researchers at Berkeley, using a real-to-sim-to-real pipeline they improve humanoid control by learning from real-world video content. Clever use of abundant data and activating it for robotic control learning. Beautiful paper website with rich video examples, do click!
State Space Models have lagged behind Transformer based models in certain skill areas, the co-inventor of the SSM model (Albert Gu) shares in this paper what could be the cause of the perceived gap.
PENCIL: Long Thoughts with Short Memory
Novel approach to Long CoT with an integrated reduction mechanism that discards thoughts that are no longer needed. This avoids the explosion of the sequence length leading to higher inference efficiency. From the paper "PENCIL achieves 97% accuracy on the challenging Einstein's puzzle -- a task even large models like GPT-4 struggle with -- using only a small 25M-parameter transformer with 2048 context length"
A thorough investigation of the effectiveness of Chatbot Arena, showing what most already expected: "systematic issues that have resulted in a distorted playing field"
📚 Resources
VRAM & Performance Calculator for local inference
Very neat tool for local inference, they have a bunch of hardware and models to see how much you need for local inference and training. I think the simulator for an intuitive "is this token speed sufficient" is a cool idea.
[Video] Latent Space Podcast episode Claude Code: Anthropic's CLI Agent
With coding agents heating up (Windsurf got acquired by OpenAI for $3B) it's interesting to hear more about Claude Code, Anthropic's terminal based coding agent, from the "horse's mouth". Boris (lead eng.) and Cat (lead PM) discuss Claude Code with swyx and Alessio from the Latent Space podcast. An interesting design choice is to align well with UNIX principles, which may end up making it more powerful by building on top of a paradigm that has really stood the test of time.
AI 2027: an exploration of how AI might evolve
Great read. Not necessarily because it's fully accurate, but because it paints a visceral picture of how society might operate when we reach more advanced levels of AI. This trajectory isn't guaranteed to play out but it helps to think about the impact of advanced AI systems. The emphasis on AI research agents and how they can accelerate AI development leading to a fast feedback loop that can lead to rapid progress has a lot of merit imo.
> Now that coding has been fully automated, OpenBrain can quickly churn out high-quality training environments to teach Agent-3’s weak skills like research taste and large-scale coordination. Whereas previous training environments included “Here are some GPUs and instructions for experiments to code up and run, your performance will be evaluated as if you were a ML engineer,” now they are training on “Here are a few hundred GPUs, an internet connection, and some research challenges; you and a thousand other copies must work together to make research progress. The more impressive it is, the higher your score.”
I thought this section was particularly prescient, as with Cursor + Gemini 2.5 Pro you can already sense that letting an agent loose on a GPU cluster and a success criteria (train a model that achieves goal X, you're allowed to use all ML engineering tricks you know) is not an unrealistic setup, in fact, this might work pretty well today with the right harness.Interesting to see which models are actually being used, a nice proxy for evals that is significantly harder to game.
Perplexity research: RL training for math reasoning
Nice in-depth walkthrough of how they tried to train a model to improve on math performance using the latest RL approaches (GRPO).
Andrej Karpathy vibe codes a menu image generation app
>But the most interesting part to me was that I didn't even spend all that much work in the code editor itself. I spent most of it in the browser, moving between tabs and settings and configuring and gluing a monster. All of this work and state is not even accessible or manipulatable by an LLM - how are we supposed to be automating society by 2027 like this? This struck a cord with me, the bottleneck of development is not in the IDE but in the stack around the IDE. Lots of whitespace here for building better more AI native experiences.
Cool to see this material publicly available, researchers from top labs (e.g. Anthropic) talk about how they believe we can develop and deploy safe AI systems, even as models get more capable (and hence potentially more dangerous). Path to safe AGI unlocked? Well, WIP.
Want more? Follow me on X! @ricklamers