
Solid papers on finetuning & interpretability and some great demos 📱
Week 22 of Coding with Intelligence

📰 News
📦 Repos
Approaching ElevenLabs level
📄 Papers
Paper claims: Your Transformer is Secretly Linear
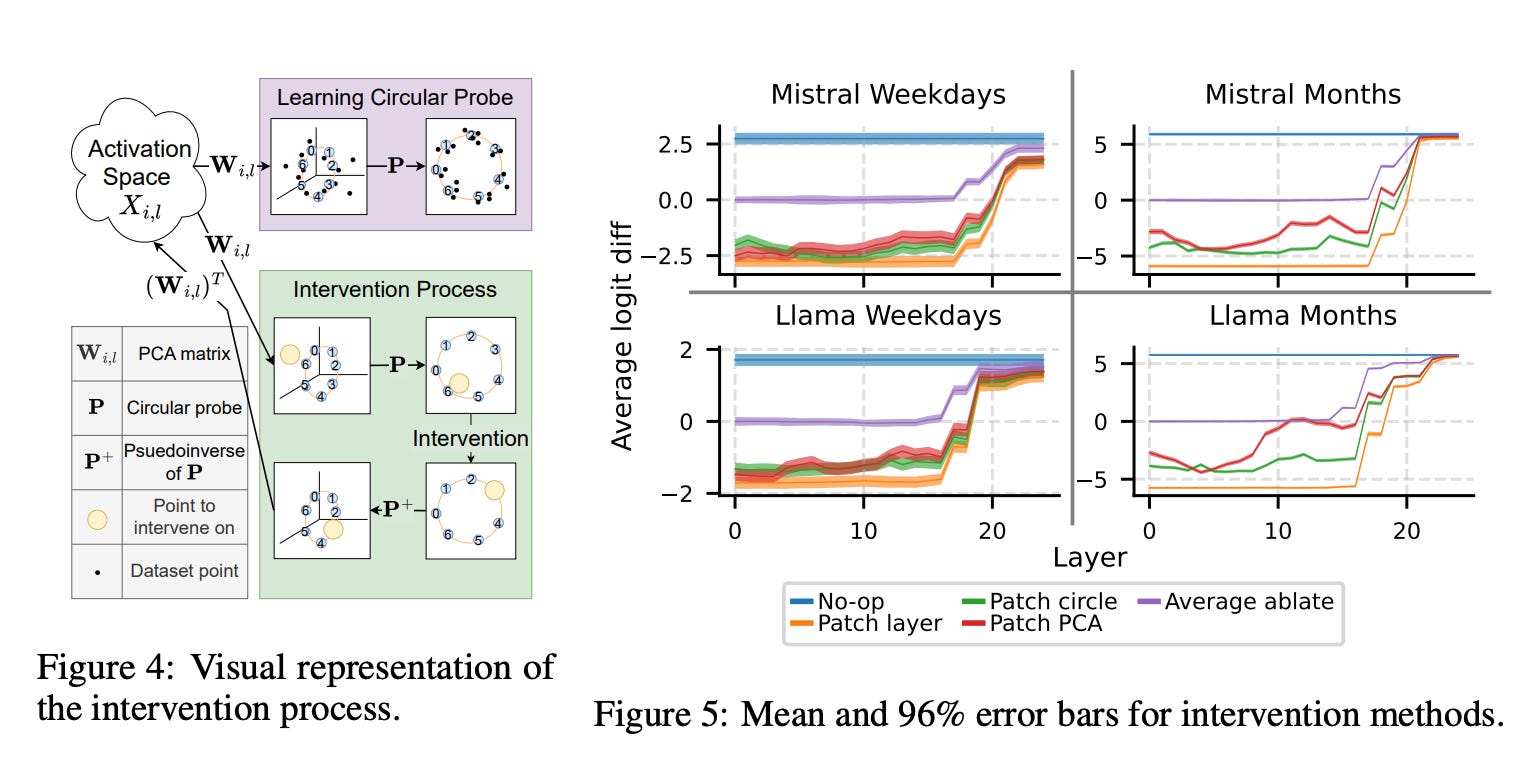
Counter claim (I buy this more): Not All Language Model Features Are Linear
"In contrast, we explore whether some language model representations may be inherently multi-dimensional. ... We identify tasks where these exact circles are used to solve computational problems involving modular arithmetic in days of the week and months of the year."
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
Significantly outperforms many vision language models like GPT-4V, LLaVA-NeXT, Gemini-Pro 1.0.
Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
"For example, compared to a conventionally trained 7B model using 300B tokens, our Gstack model converges to the same loss with 194B tokens, resulting in a 54.6% speedup.“
Quantifying In-Context Reasoning Effects and Memorization Effects in LLMs
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
SimPO: Simple Preference Optimization with a Reference-Free Reward
Beats DPO in certain cases
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
LoRA alternative better suited for continued pre-training/absorbing new knowledge.
📱 Demos
AI Draw Something guesser 🔥 Awesome work by @geeksplainer
Real-time conversing with digital clones
Very impressive demo, looks like it's running fully locally. Clearly some uncanny valley stuff and ethical considerations are needed here. Elon drops in mid-way.
📚 Resources
A Guide to Creating Neural Circuit Diagrams
By Vincent Abbott (@vtabbott_ on X)
Good comparison of fine-tunes across various open source models like Llama 3 8B and Phi 3 for a variety of downstream tasks.
What We Learned from a Year of Building with LLMs (Part I)
By Eugene Yan, Bryan Bischof, Charles Frye, Hamel Husain, Jason Liu and Shreya Shankar
Interestingly it has a private held out test set so overfitting is less likely. The obvious downside if you have to put trust in Scale, which has a pretty good track record so feels acceptable.
Want more? Follow me on X! @ricklamers