
Special announcement: Llama 3 Groq Tool Use finetunes 8B and 70B
New #1 Berkeley Function Calling Leaderboard model

I’ve been leading a secret project for months … and the word is finally out:
🛠️ I'm proud to announce the Llama 3 Groq Tool Use 8B and 70B models 🔥

An open source Tool Use full finetune of Llama 3 that reaches the #1 position on BFCL beating all other models, including proprietary ones like Claude Sonnet 3.5, GPT-4 Turbo, GPT-4o and Gemini 1.5 Pro.
This has been months of hard work from me, my great colleagues at Groq and our awesome collaborators over at Glaive.
The model has been trained on synthetic data only. This is a powerful full finetune, not a LoRA. Yes, we've checked rigorously for overfitting using the LMSYS described robust decontamination techniques, they only score 5.6% on SFT synthetic data and 1.3% on synthetic DPO data.
Now available on the Groq API for blazing fast speeds of 1050 tok/s for 8B (that’s over 7 tool call chat completions per second, each in less than 150ms) and 330 tok/s for the 70B model or download the open source weights from Hugging Face to start exploring & tinkering.
You can try out a demo calculator enabled chat app here.
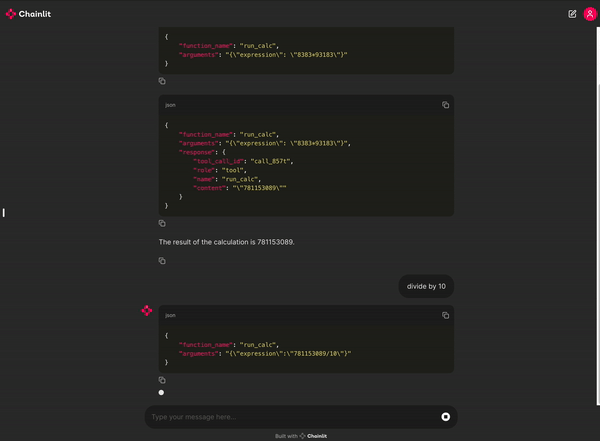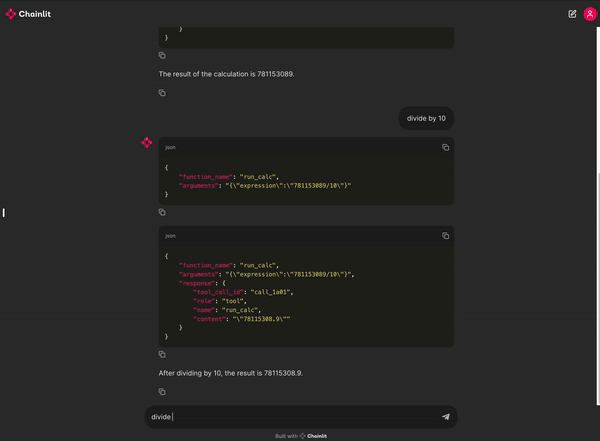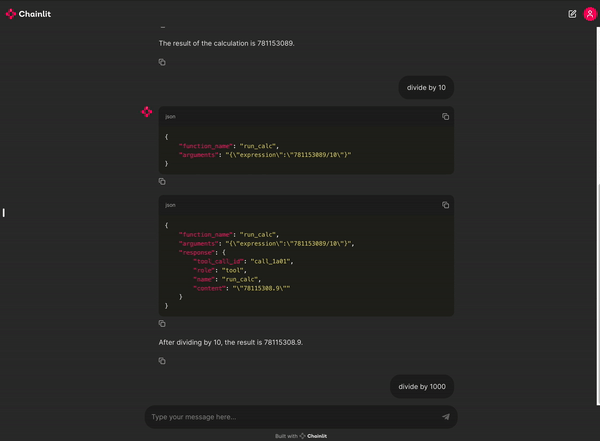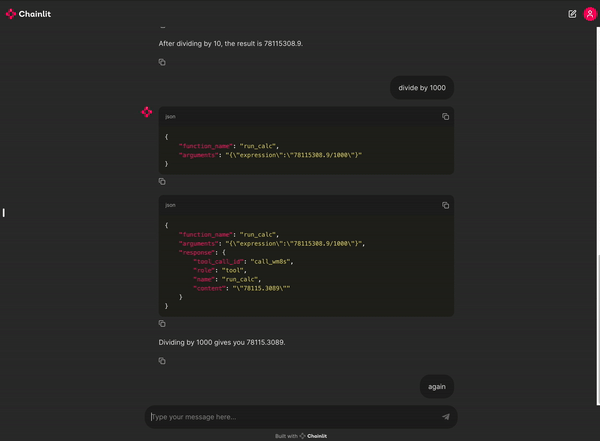
Check out the full blog post for more details.
Links:
https://wow.groq.com/introducing-llama-3-groq-tool-use-models/
https://chainlit-tool-use-demo-groqcloud.replit.app/
https://console.groq.com/
https://huggingface.co/Groq/Llama-3-Groq-8B-Tool-Use
https://huggingface.co/Groq/Llama-3-Groq-70B-Tool-Use
* What’s with the (FC)/(Prompt) thing? The BFCL uses the function calling APIs of models that have it available but also uses their custom tool use prompt. That custom prompt version isn’t actually what you’re getting if you’re using the model through the model provider API endpoint for function calling in e.g. libraries like LangChain, so in a way our finetuned Llama 3 70B function calling endpoint on the Groq API represents an even larger improvement over the previously best FC API endpoint which is Gemini-1.5-Pro-Preview-0514 (FC) at 86.35% and our score of 90.71% (FC).